Bayesian optimization deep learning
Introduction:
The picture of Bayesian optimization is obtianed from here
Bayesian optimization
There are a lot of hyperparameters for machine learning models such as NN. Typically, random or grid search are effecient ways to conduct the optimization of models. They can be very time-consuming in some cases which waste time on unpromising areas of search space. Bayesian optimization can overcome this problem by adopting an informed seach method in the space to find the optmized parameters.
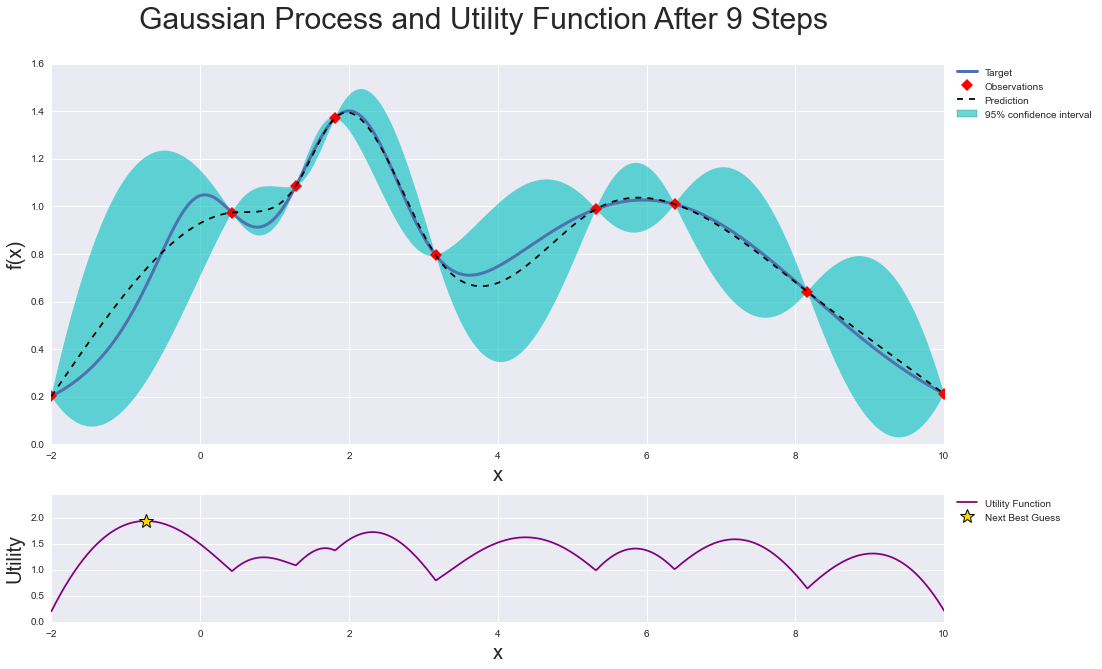
Bayesian optimization works by constructing a posterior distribution of functions (gaussian process) that best describes the function you want to optimize. As the number of observations grows, the posterior distribution improves, and the algorithm becomes more certain of which regions in parameter space are worth exploring and which are not. You can find more information and explination here
It’s worthy to note that the Bayesian optimization is to find the maximum of a function. Thus, when we formulate a function and evaulation metrics, we should take this part into consideration. For example, when we used log loss to evaluate our model performance, the smaller values will be better. We should return a negative logloss to make it suitable for maximum of the defined function.
Note: It took a long time to run if you have a big dataset and wide boundary. You can refer to Colab for running the code.
Project link: https://github.com/tankwin08/Bayesian_optimization_deep_learning